


- Что такое файл robots.txt? Файл robots.txt - это просто TXT-файл, который находится в корне вашего...
- Почему этот файл так важен?
- Вам это технически нужно?
- Robots.txt форматирование и правила
- Директивы
- Карта сайта Ссылка
- Лучшие практики для настройки вашего файла robots.txt для SEO?
- 2. Исключите только те файлы и каталоги сайта, которые вы не хотите индексировать
- 3. Не запрещайте доступ ко всему сайту, если вы действительно не хотите, чтобы он сканировался
- 4. Не блокируйте файлы CSS, Javascript или Image с помощью файла robots.txt (если для этого нет особых причин)
- 5. Всегда включайте ссылку на местоположение вашего основного XML-файла Sitemap или индекса Sitemap.
- 6. Ознакомьтесь с предлагаемыми правилами robots.txt, используя инструмент тестирования Google Robots.txt,...
- 7. Регулярно просматривайте (и обновляйте при необходимости) файл robots.txt, чтобы убедиться в отсутствии...
- 8. Используйте вместе с тегом noindex на странице для лучшего контроля индексации.
- Рекомендуемая конфигурация для WordPress?
- Дополнительные ресурсы Robots.txt
Что такое файл robots.txt?
Файл robots.txt - это просто TXT-файл, который находится в корне вашего сайта и предоставляет поисковым системам информацию о том, какие части вашего сайта им разрешено сканировать.
Что еще более важно, он сообщает веб-роботам, какие области сайта вам не нужны.
Несколько исторических и практических заметок о стандарте файла robots.txt:
- /Robots.txt является стандартом де-факто и не принадлежит ни одному органу по стандартизации. Есть два исторических описания: оригинал 1994 Стандарт для исключения роботов документ и проект спецификации на Интернет в 1997 году Способ управления веб-роботами
- Некоторые дополнительные внешние ресурсы: Спецификация HTML 4.01 Приложение B.4.1 и Википедия - стандарт исключения роботов
- Разные сканеры могут по-разному интерпретировать синтаксис
- Стандарт /robots.txt активно не разрабатывается.
- Веб-роботы могут игнорировать файл /robots.txt вашего сайта. Это особенно характерно для вредоносных роботов, которые ищут уязвимости в безопасности.
- Файл /robots.txt является общедоступным файлом. Это означает, что любой может увидеть, какие разделы вашего сервера вы не хотите использовать роботам, поэтому не пытайтесь использовать /robots.txt, чтобы скрыть информацию.
- Ваши директивы robots.txt не могут запретить ссылки на ваши URL-адреса с других сайтов.
Где вы можете найти файл robots.txt?
В корневой директории вашего сайта. Как пример, вот мой:
Почему этот файл так важен?
Файл robots.txt напрямую управляет индексацией, и при неправильном обращении может привести к полной деиндексации вашего сайта (или частей вашего сайта) или субоптимальному отображению на страницах результатов поисковой системы (SERP).
Хотя это, конечно, не самый гламурный аспект SEO, ваш файл robots.txt может сильно повлиять на производительность SEO.
Вам это технически нужно?
Нет, отсутствие файла robots.txt не помешает поисковым системам сканировать ваш сайт.
Тем не менее, я настоятельно рекомендовал бы иметь такой, поскольку он уже более 20 лет является веб-стандартом, он может позволить вам контролировать индексацию вашего сайта, и вы можете использовать его для отправки критических страниц поисковым системам через вашу карту сайта XML.
Robots.txt форматирование и правила
Агенты пользователей
Во-первых, все файлы robots.txt должны иметь пользовательский агент, который определяет, к каким разделам должны применяться правила.
Использование агента пользователя [su_highlight]: * [/ su_highlight] применяется ко всем веб-роботам.
Пользователь-агент: *
Тем не менее, вы можете ориентироваться на конкретных ботов с определенными правилами. Вот пример того, как настроить таргетинг на [su_highlight] робот Google [/ su_highlight]:
Пользователь-агент: Googlebot
Смотрите список все пользовательские агенты / веб-роботы , Как примечание, вы можете включить несколько пользовательских агентов с уникальными правилами для каждого в одном файле robots.txt.
Директивы
Ниже приведены некоторые примеры использования файла robots.txt для управления индексацией вашего сайта или определенных папок.
Чтобы запретить сканерам доступ ко всему контенту сайта
Пользователь-агент: * Disallow: /
Разрешить сканерам доступ ко всему контенту сайта
Пользователь-агент: * Disallow:
Чтобы исключить сканеры из доступа к определенным папкам и страницам
Пользовательский агент: * Disallow: / wp-content / Disallow: / wp-plugins / Disallow: /example-folder/example.html
Чтобы исключить одного робота из сканирования, но разрешить другим
User-agent: * Disallow: User-agent: Baiduspider Disallow: /
Чтобы исключить доступ к определенной папке, но разрешить определенные типы файлов
User-agent: * Disallow: / example / Allow: /example/*.jpg Разрешить: /example/*.gif Разрешить: /example/*.png Разрешить: /example/*.css Разрешить: /example/*.js
Хотя технически нет атрибута [su_highlight] Allow [/ su_highlight], я использовал этот метод, и он работает.
Фактически, вот пример скриншота того, как он работает на моем сайте (согласно инструменту Google Robots.txt).
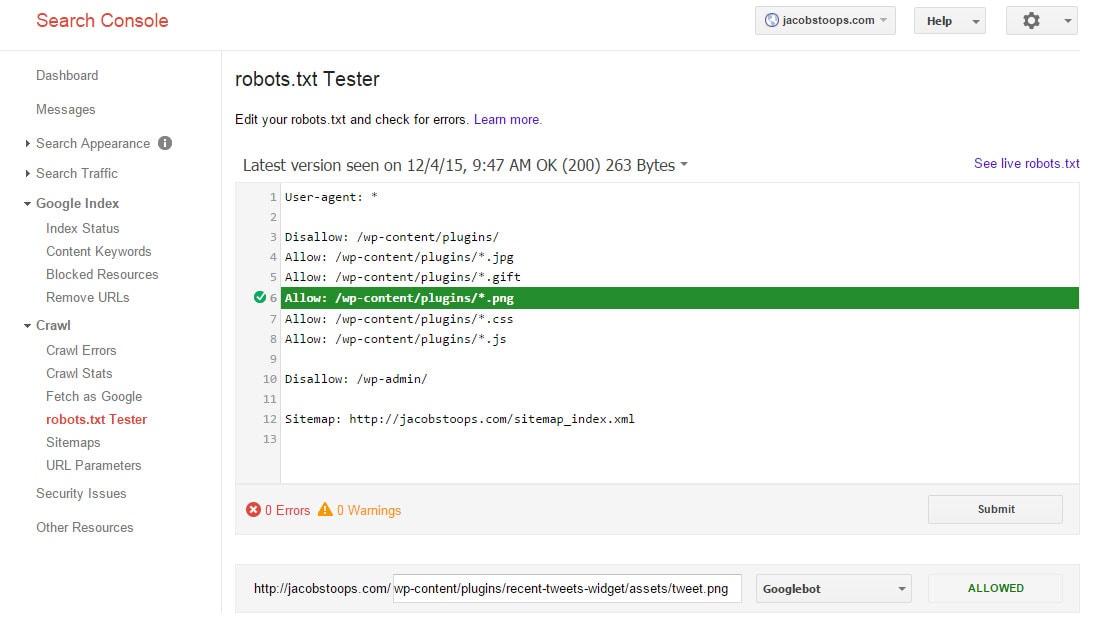
Чтобы разрешить доступ к определенной папке, но исключить определенные типы файлов
Как раз противоположность вышеуказанному методу.
Пользовательский агент: * Разрешить: / wp-content / plugins / Disallow: /wp-content/plugins/*.png
Запретить доступ к файлу определенного типа
Пользовательский агент: * Disallow: /*.gif$
Конечно, есть и другие способы настройки файла robots.txt, но они должны помочь вам начать работу.
Карта сайта Ссылка
Ниже приведен формат для добавления ссылки на карту сайта XML вашего сайта.
Пользователь-агент: * Disallow: Карта сайта: https://jacobstoops.com/sitemap_index.xml
Лучшие практики для настройки вашего файла robots.txt для SEO?
1. Он должен называться robots.txt, должен быть файлом TXT и должен находиться в корневом каталоге вашего сайта (например, example.com/robots.txt).
Вы должны применить следующие соглашения о сохранении, чтобы сканеры могли найти и идентифицировать ваш файл robots.txt. Например, поскольку сканеры ищут этот файл только в корневом каталоге сайта, если вы сохраните его в подкаталоге (например, example.com/directory/robots.txt), он не будет его использовать.
2. Исключите только те файлы и каталоги сайта, которые вы не хотите индексировать
Например, если у вас есть каталоги, которые могут привести к проблемам с дублированием контента, вы можете использовать файл robots.txt для управления их индексацией.
Кроме того, возможно, разумно запретить индексирование файлов, которые будут содержать конфиденциальные данные, такие как номера телефонов, информация о транзакциях и т. Д. (Хотя эти вещи, вероятно, лучше контролируются через HTTPS).
3. Не запрещайте доступ ко всему сайту, если вы действительно не хотите, чтобы он сканировался
Это, вероятно, самое большое «нет-нет» на стороне SEO. К сожалению, это случилось.
[su_note note_color = ”# EFEFEF”] Примеры клиентов: за мой ~ 10-летний опыт я помню, что это происходило как минимум 2 раза - один с небольшим сайтом, а другой с большим сайтом электронной коммерции. В обоих случаях сайты были практически полностью проиндексированы за определенный период, а в случае крупного сайта электронной коммерции последствия для дохода от естественного поиска были чрезвычайно серьезными.
Также в обоих случаях изменения произошли от кого-то за пределами команды SEO, что намекает на то, что, возможно, они не полностью поняли, что делают. Оба случая были неудачными неудачами для соответствующих программ SEO. [/ Su_note]
4. Не блокируйте файлы CSS, Javascript или Image с помощью файла robots.txt (если для этого нет особых причин)
В октябре 2014 года Google обновил свои технические рекомендации для веб-мастеров по индексированию CSS, JavaScript, изображений и т. д. ,
Вот что они сказали:
[su_quote] Запрещение сканирования файлов Javascript или CSS в файле robots.txt вашего сайта напрямую вредит тому, насколько хорошо наши алгоритмы отображают и индексируют ваш контент, и может привести к неоптимальному ранжированию. [/ su_quote]
Чтобы проверить, не блокируете ли вы какие-либо важные ресурсы, вы можете воспользоваться отчетом о заблокированных ресурсах Google Search Console:
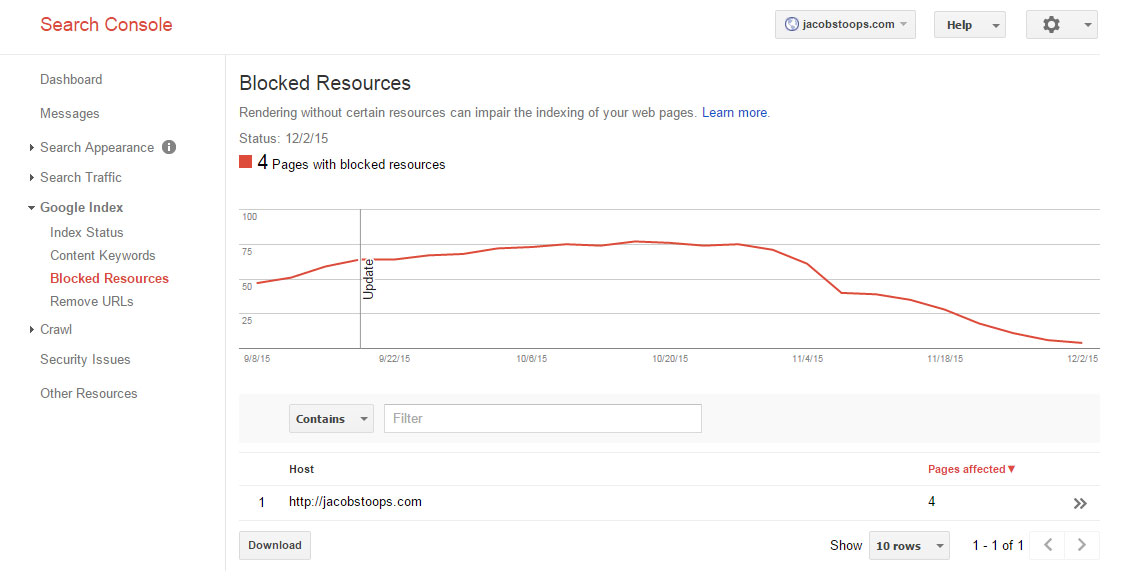
5. Всегда включайте ссылку на местоположение вашего основного XML-файла Sitemap или индекса Sitemap.
Это отличный способ для поисковых систем получить доступ к XML-карте сайта вашего сайта, особенно если вы еще не отправили ее через консоль поиска Google.
6. Ознакомьтесь с предлагаемыми правилами robots.txt, используя инструмент тестирования Google Robots.txt, перед публикацией в реальном времени.
Это поможет убедиться, что никакие важные страницы не блокируют случайно доступ поисковой системы.
Увидеть: https://support.google.com/webmasters/answer/6062598?hl=en&ref_topic=6061961
7. Регулярно просматривайте (и обновляйте при необходимости) файл robots.txt, чтобы убедиться в отсутствии проблем.
Многое может произойти в ходе развертываний, выпусков кода и т. Д. Просмотр вашего файла robots.txt в комбинации даст такие инструменты, как Google Search Console может помочь вам обеспечить правильную обработку индексации и конфигурации файла robots.txt на вашем сайте.
8. Используйте вместе с тегом noindex на странице для лучшего контроля индексации.
Блокирование URL-адресов при индексации через файл robots.txt может не запрещать этим страницам / файлам отображаться как списки только URL-адресов в поисковой выдаче, особенно если страницы были проиндексированы до их исключения.
Если страница уже проиндексирована, но заблокирована - в поисковой выдаче появится следующее сообщение:
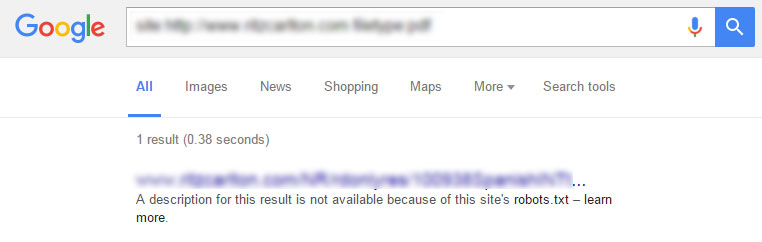
Лучшее решение для полной блокировки индекса конкретной страницы - использовать тег [su_highlight] robots meta noindex [/ su_highlight] для каждой страницы вместе с файлом robots.txt.
Это лучший способ остановить попадание страниц в индекс в первую очередь или получить уже проиндексированные страницы для удаления.
Рекомендуемая конфигурация для WordPress?
Если вы используете WordPress, довольно легко отредактировать файл robots.txt, используя либо FTP, либо с помощью плагина, такого как Yoast SEO for Worpress. Просто выполните следующие шаги, чтобы внести изменения в ваш файл robots.txt ,
С точки зрения наилучшего способа настройки существует множество способов снятия шкуры с кошки.
Вот как я настроил мой:
Пользовательский агент: * Disallow: / wp-content / plugins / Allow: /wp-content/plugins/*.jpg Разрешить: /wp-content/plugins/*.gif Разрешить: /wp-content/plugins/*.png Разрешить: /wp-content/plugins/*.css Разрешить: /wp-content/plugins/*.js Запретить: / wp-admin / Карта сайта: https://jacobstoops.com/sitemap_index.xml
Я гарантировал, что ключевой контент будет сканироваться, но эта конфигурация гарантирует, что ключевые каталоги блокируются, в то же время позволяя индексировать такие вещи, как Javascript, CSS и изображения.
Я также включил ссылку на мой индексный файл XML-карты сайта.
Дополнительные ресурсы Robots.txt
Кредит изображения: Drive Электронные новости
Txt?Почему этот файл так важен?
Вам это технически нужно?
Txt для SEO?
Рекомендуемая конфигурация для WordPress?
Txt?
Txt?
Вам это технически нужно?
Txt для SEO?
Com/webmasters/answer/6062598?



